环境准备
开发环境
本页总结了数据开发项目所需的准备工作,前提已经完成开发前准备 和安装Cookiecutter。
快速上手示例项目使用Pyspark进行开发,可以通过Pypi 安装PySpark如下:
本地运行PySpark项目时环境依赖Hadoop 和JDK,需要安装并配置环境变量
环境变量路径问题
如JAVA_HOME,HADOOP_HOME环境变量,路径中不要带有空格或中文,避免加载时报错
安装Hadoop
建议使用解压工具对.tar.gz文件格式进行解压,如Bandizip
在Windows PowerShell 运行tar -zxvf
中可能发生Maximum Path Length Limitation
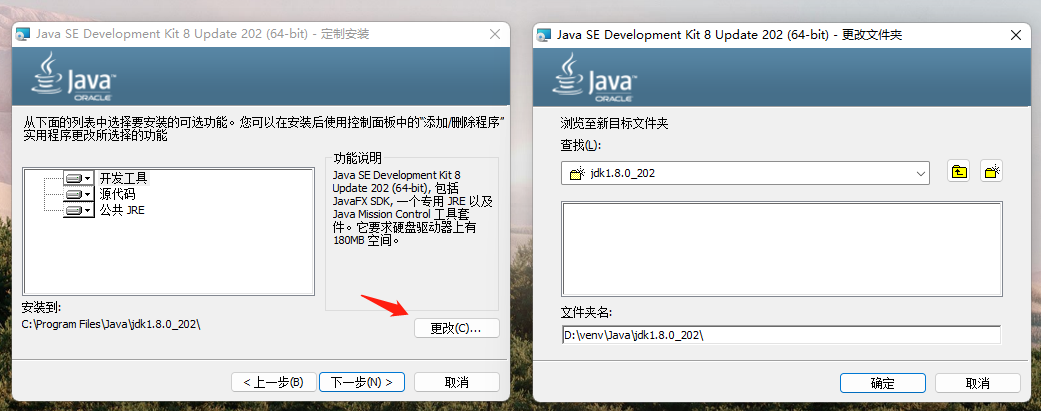
安装JDK
下载JDK安装包,建议统一管理开发环境,更改安装路径。
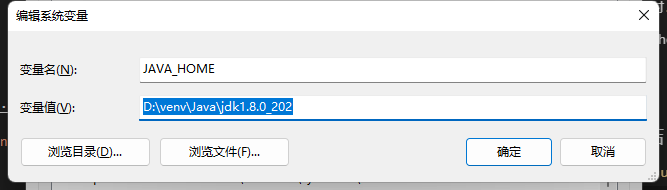
配置环境变量
配置JAVA_HOME
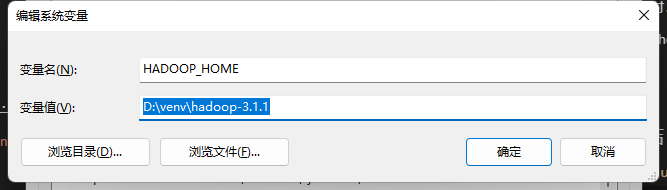
配置HADOOP_HOME
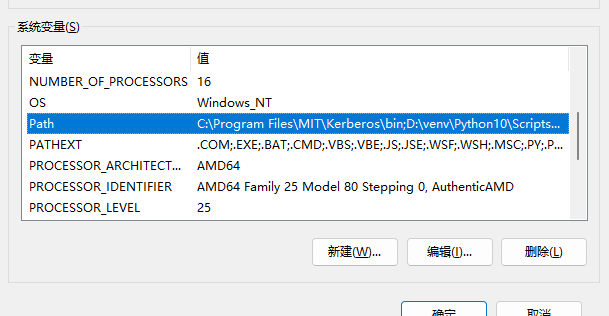
配置%JAVA_HOME%/bin,%HADOOP_HOME%/bin
常见问题总结
问题1 (缺少winutils.exe, hadoop.dll)
22/08/25 13:51:47 tid: [main] WARN org.apache.hadoop.util.Shell -
Did not find winutils.exe: {}
java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
at org.apache.hadoop.util.Shell.fileNotFoundException(Shell.java:548)
at org.apache.hadoop.util.Shell.getHadoopHomeDir(Shell.java:569)
at org.apache.hadoop.util.Shell.getQualifiedBin(Shell.java:592)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:689)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:78)
at org.apache.hadoop.fs.FileSystem$Cache$Key.<init>(FileSystem.java:3609)
at org.apache.hadoop.fs.FileSystem$Cache$Key.<init>(FileSystem.java:3604)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:3441)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:524)
at org.puppy.hadoop.app.HDFSApplication.main(HDFSApplication.java:26)
Caused by: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.
at org.apache.hadoop.util.Shell.checkHadoopHomeInner(Shell.java:468)
at org.apache.hadoop.util.Shell.checkHadoopHome(Shell.java:439)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:516)
... 6 common frames omitted
解决方案:
Windows在安装Hadoop环境时可能会遇到缺少文件winutils.exe和hadoop.dll
,可以通过github下载Hadoop文件
,将安装时缺少的文件,放入%Hadoop%/bin目录下,重启IDE。
(如果还不成功的话可以尝试)将hadoop.dll复制到C:\Window\System32下
问题2 (Python worker failed to connect back.)
22/08/25 13:51:47 ERROR Executor: Exception in task 0.0 in stage 2.0 (TID 2)
org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:189)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:164)
at org.apache.spark.sql.execution.python.BatchEvalPythonExec.evaluate(BatchEvalPythonExec.scala:81)
at org.apache.spark.sql.execution.python.EvalPythonExec.$anonfun$doExecute$2(EvalPythonExec.scala:130)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitions$2(RDD.scala:855)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitions$2$adapted(RDD.scala:855)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.SocketTimeoutException: Accept timed out
at java.net.DualStackPlainSocketImpl.waitForNewConnection(Native Method)
at java.net.DualStackPlainSocketImpl.socketAccept(DualStackPlainSocketImpl.java:135)
at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:409)
at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:199)
at java.net.ServerSocket.implAccept(ServerSocket.java:545)
at java.net.ServerSocket.accept(ServerSocket.java:513)
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:176)
... 24 more
解决方案:
全局增加环境变量或IDE增加环境变量,增加内容如下:
问题3 (Poetry下载资源"gbk" 格式异常)
The following packages are already present in the pyproject.toml and will be skipped:
'gbk' codec can't encode character '\u2022' in position 2: illegal multibyte sequence
解决方案:
Windows系统语言设置为utf-8格式